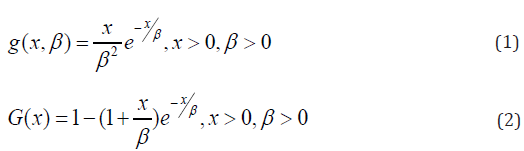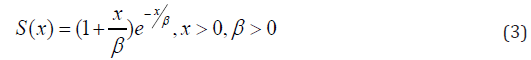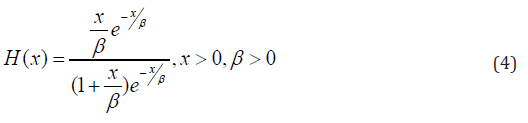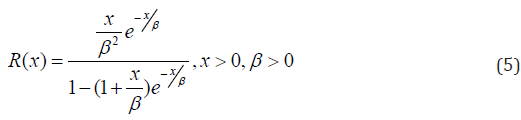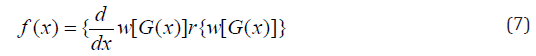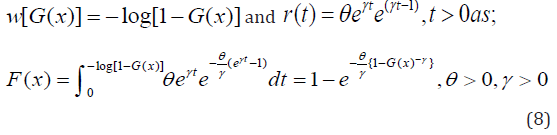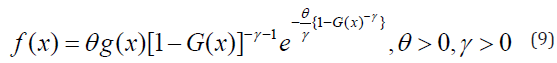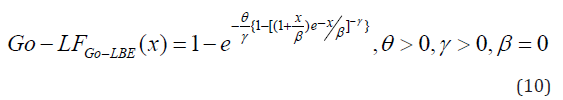In this article, block and row-column designs for genetic crosses such as Complete diallel cross system using orthogonal arrays
(p2, r, p, 2), where p is prime or a power of prime and semi balanced arrays (p(p-1)/2,
p, p, 2), where p is a prime or power of an odd
prime, are derived. The block designs and row-column designs for
Griffing’s methods A and B are found to be A-optimal and the
block designs for Griffing’s methods C and D are found to be universally
optimal in the sense of Kiefer. The derived block and rowcolumn
designs for method A and C are new and consume minimum experimental
units. According to Gupta block designs for
Griffing’s methods A,B,C and D are orthogonally blocked designs. AMS
classification: 62K05.
Keywords: Orthogonal Array; Semi-balanced Array; Complete diallel Cross; Row-Column Design; Optimality
Introduction
Orthogonal arrays of strength d were introduced and applied
in the construction of confounded symmetrical and asymmetrical
factorial designs, multifactorial designs (fractional replication)
and so on Rao [1-4] Orthogonal arrays of strength 2 were found
useful in the construction of other combinatorial arrangements.
Bose, Shrikhande and Parker [5] used it in the disproof of Euler’s
conjecture. Ray-Chaudhari and Wilson [6-7] used orthogonal arrays
of strength 2 to generate resolvable balanced incomplete block
designs. Rao [8] gave method of construction of semi-balanced
array of strength 2. These arrays have been used in the construction
of resolvable balanced incomplete block design. A complete diallel
crossing system is one in which a set of p inbred lines, where p
is a prime or power of a prime, is chosen and crosses are made
among these lines. This procedure gives rise to a maximum of v =p2
combination. Griffing [9] gave four experimental methods:
parental line combinations, one set of F1’s hybrid and
reciprocal F1’s hybrid is included (all v = p2 combination)
parents and one set of F1’s hybrid is included but reciprocal
F1’s hybrid is not (v = 1/2 p(p+1) combination)
one set of F1’s hybrid and reciprocal are included but not
the parents (v =p(p-1) combination) and
one set of F1’s hybrid but neither parents nor reciprocals
F1’s hybrid is included (v = 1/2p(p-1). The problem of generating
optimal mating designs for CDC method D has been investigated
by several authors Singh, Gupta, and Parsad [10].
For CDC method A, B and C models of Griffing [9] involves the
general combining ability (g ca) and specific combining ability (sca)
effects of lines. Let nc denote the total number of crosses involved
in CDC method A, B and C and it is desired to compare the average
effects or g ca effects of lines. Generally, the experiments of these
methods are conducted using either a completely randomized
design (CRD) or a randomized complete block (RCB) design
involving nc crosses as treatments. The number of crosses in such
mating design increases rapidly with an increase in the number
of lines p. Thus, if p is large adoption of CRD or an RCB design is
not appropriate unless the experimental units are extremely
homogeneous. It is for this reason that the use of incomplete block
design as environment design is needed for CDC method A, B and
C. Agarwal and Das [11] used n-ary block designs in the evaluation
of balanced incomplete block designs for all the four Griffing’s [9]
complete diallel cross (CDC) systems. Optimal block designs for
CDC method a and b and variance balanced designs for CDC method
c have been constructed by Sharma and Fanta [12,13] but their
designs consume more experimental units. This call designs for CDC methods A, B and C which consume less experimental units
in comparison to their designs and at the same time are A-optimal
or optimal. We restrict here to the estimation of general combining
ability (gca) effects only. For analysis of these designs [12-14].
I in the present paper, we are deriving block and row-column
designs for complete diallel cross (CDC) system i.e. methods A, B, C
and d through orthogonal arrays and semi balanced arrays. Block
designs and row-column designs obtained for methods a consume
minimum experimental units and are A-optimal. Block designs
obtained for method C are optimal in the sense of Kiefer [15] and
consume minimum experimental units but row-column designs
are neither A-optimal nor optimal. Conversely block designs and
row-column designs obtained for methods B are A-optimal. Block
designs obtained for method D are optimal in the sense of Kiefer
[15] but row-column designs are neither A-optimal nor optimal.
The rest of this article is organized as follows: in section B and C
we have discussed universal optimality of designs for 1-way and
2-way settings. In section 4 and 5, we give some definitions of
orthogonal array, semi balanced arrays and orthogonally blocked
design and relation of orthogonal; array with designs for CDC
system and optimality with examples and theorems. In section 6
we give relation of semi-balanced array to CDC system along with
theorem and for example.
Model and Estimation in 1-Way Heterogeneity
Setting
According to Sharma and Tadesse let d be a block design for a
CDC systems experiment involving p inbred lines, b blocks each of
size k. This means that there are k crosses in each of the blocks of
d. Further, let rdt and sdi denote the number of replications of cross
t and the number of replications of the line i in different crosses,
respectively, in d [ t = 1,2, …, nc; i = 1, 2, …, p]. It is not hard to see
that,

nc = number of crosses and n = bk, the total number of
observations. For estimating general combining ability (gca) effects
of lines, we took the following linear model for the observations
obtained from block design d.

where y is an n×1 vector of observations, 1n is the n×1 vector of
ones, △′1 is the n × p design matrix for lines and △′2 is an n × b design
matrix for blocks, that is, the (h,λ)th element of △′1 ( respectively,
of △′1) is 1 if the hth observation pertains to
the lth line (respectively,
of block) and ois zero otherwise. μ is a general mean, g is a p × 1
vector of line parameters, Β is a b × 1 vector of block parameters
and e is an n × 1 vector of residuals. It is assumed that the vector of
block parameter, Β is fixed and e is normally distributed with

where I is the identity matrix of conformable order. Using least
squares estimation theory with usual restriction  , we
shall have the following reduced normal equations for the analysis
of proposed design d, for estimating the general combining ability
(gca) effects of lines under model (2.1).
, we
shall have the following reduced normal equations for the analysis
of proposed design d, for estimating the general combining ability
(gca) effects of lines under model (2.1).

In the above expressions, Gd =△1 △′1 = (gdii´), gdii = sdi and for i ≠i´,
gdii´ is the number of crosses in d in which the linesi and i´ appear
together. Nd= △1△′2 = (ndij), ndij is the number of times the line i occurs
in block j of d and Kd = △2△′2 is the diagonal matrix of block sizes. T
= △′1 y and B = △′2 y are the vectors of lines totals and block totals
of order p × 1 and b × 1, respectively for design d. A design d will be
called connected if and only if rank (Cd) = p -1, or equivalently, if and
only if all elementary comparison among general combining ability
(gca) effects are estimable using d. We denote by D (p, b, k), the class
of all such connected block design {d} with p lines, b blocks each
of size k. In section 3, we will discuss Kiefer’s [15] criterion of the
universal optimality of D (p, b, k).

Where y is an n × 1 vector of observed responses, μ is the general
mean, g, Β and ã are column vectors of p general combining ability
(gca) parameters, k row effects and b column effects, respectively,
△1(n× p), △'2(n× k), △'3(n×b) are the corresponding design
matrices, respectively and e denotes the vector of independent
random errors having mean 0 and covariance matrix
σ2In.LetNd1 =
△1 △'2 be the p × k incidence matrix of lines vs rows and Nd2 = △1 △'3
be the p × b incidence matrix of treatments vs columns and △1△'3=
1k1b.Let rdl denote the number of times the lth cross appears in the
design d, λ = 1, 2, . . . , nc and similarly sdi denote the number of times
the ith line occurs in design d, i = 1, . . . p. Under (3.1), it can be shown
that the reduced normal equations for estimating the gca effects of
lines with usual restriction
 , after eliminating the effect of
rows and columns, in block design d are
, after eliminating the effect of
rows and columns, in block design d are

is the number of times line i occurs in row j of d, Nd2= (ndi.t),
ni.t is the number of times the cross i occurs in column t,
sd1 is the replication vector of lines in design d,
Q is a p × 1 vector of adjusted treatments (crosses) total,
T is a p × 1 vector of treatment (line) totals,
R is a k × 1 vector of rows totals,
C is a b ×1 vector of columns totals, respectively, in design d,
G is a grand total of all observations in design d,
Now we state the following theorem of Parsad et al. [16]
without proof.
Theorem: Let d* ∈ D1 (p, b, k) be a row - column design and d* ∈
D (p, b, k) be a block design for diallel crosses satisfying
(i) Trace (Cd*) = k-1b {2 k (k-1-2x) + p x (x+1)
(ii) (Cd*) = (p-1)-1k--1 b {2 k (k -1-2x) + p x (x+1)} (Ip - p-1 1p
1′p) is completely symmetric.
Where x = [2k/p], where [z]is the largest positive integer not
exceeding z, Ip is an identity matrix of order p and 1p1′p is a p ×
p matrix of all ones. Then according to Kiefer [15], d*ɛ D1 (p, b, k)
or d*∈ D (p, b, k) is universally optimal and in particular minimizes
the average variance of the best linear unbiased estimator of all
elementary contrasts among the gca effects. Furthermore, using
d*ɛ D1 (p, b, k) or d*∈ D (p, b, k) all elementary contrasts among gca
effects are estimated with variance.

Some Definitions
Definition 4.1: According to Bose and Bush [17], an r × N
matrix A, with entries from a set ∑ of p ≥ 2 elements is called an
orthogonal array of strength d, size N, r constraints and p levels if
d × N sub matrix of A contains all possible × 1 column vectors with
the same frequency λ. The array may be denoted by (N, r, p, d). The
number λ may be called the index of the array. Clearly N = λ pd.
Definition 4.2: According to Rao [8], a (N, r, p) array is said to
be a semi-balanced array of strength d if for any selection of d rows
α1, α2, . . . , αd, we denote d rows by n(i1, i2, . . ., id).
(i) n (i1, i2, . . ., id) = 0 if any two ij are equal.

Where s represents summation over all permutation of distinct
elements i1 , i2, . . ., id.
Definition 4.3: According to Gupta et al. [18], a diallel cross
design to be orthogonally blocked if each line occurs in every block
r/b time, where r is the constant replication number of the lines
and b is the number of blocks in the design.
Relation between Orthogonal Array (p2, p+1, p, 2)
and Designs for CDC System
Consider an orthogonal array (p2, p+1, p, 2), where p is a prime
or power of a prime. If we divide this array into p groups where each
group contains p × (p+1) elements and identify the elements of each
group as p lines of a diallel cross experiments. Now we perform
crosses in any two columns of (p+1) constraints in first group and
perform crosses among the lines appearing in the corresponding
columns in (p-1) groups, we get p initial columns blocks as given
below, which can be developed cyclically mod(p) to get design d1
for diallel cross experiment Griffing’ s method A with p2 distinct
crosses of p parental lines consisting of p self, 1/2 p (p-1) number of
F1 crosses, and the same number of reciprocal F1’s with parameter
v = p2, b = p, k =p , r =1. By this procedure we obtain p(p+1)/2 designs
for diallel cross experiment Griffing’s method A (Table1). Note: All
column blocks will be developed cyclically mod (p).
Table 1:

Now considering in d1 , the cross of the type (i, j) = (j, i), i, j
= 1,2, . . . p, we may obtain design d2 for Griffing’s method B with
parameters v = p(p+1)/2, b =p, k =p, r1 =1,for cross of the type (i, i) and
r2 =2, for cross of the type (i, j), where i, j = 1, 2, . . ., p, respectively.
Considering rows as row blocks in block designs d1 and d2 we may
also obtain row-column designs d3 and d4 for Griffing’s methods A
and B with parameters v = p2, b = p, k =p, r =1 and v = p(p+1)/2, b =p,
k =p, r1 =1,for cross of the type (i,i) and r2 =2, for cross of the type (i,
j), where i, j = 1, 2, . . ., p, respectively. If we ignore the crosses of the
type (i, i) in d1, where i = 1, 2, . . . p, we may obtain the block design
d5 for Griffing’s method C with parameters v = p (p-1), b =p, k =p
and r =1. Considering the crosses of the type (i, j) = (j, i) in d5 we
may also derive design d6 for Griffing’s method D with parameters
v = p (p-1)/2, b =p, k =p and r =1, where i < j = 1, 2,. . ., p. Considering
rows as row blocks in block designs d5 and d6, we may also derive
row-column designs d7 and d8 for Griffing’s methods C and D with
parameters v = p (p-1), b =p, k =p , r =1 and v = p(p-1)/2, b =p, k
=p and r =1, respectively, The designs d7 and d8 are neither optimal
nor A-optimal. It is not hard to see that block and row-column
designs obtained for Griffing’s methods A and C consume minimum
experimental units and in theses designs every cross is replicated
only once and each line occurs in every block r/b time, where r is the
constant replication number of line and b is the number of blocks
in the design. In block designs for Griffing’s methods B and D each
line also occurs in every block r/b time. Hence according to Gupta
et al. [18] these designs are orthogonally blocked. In an orthogonal
design no loss of efficiency on the comparisons of interest is
incurred due to blocking. A block design for which N = θ 1p 1′b
is orthogonal for estimating the contrasts among gca parameters,
where N denotes the line versus block incidence matrix and θ is
some constant. For designs dk ∈ D (p, b, k), where k = 1, 2, 5, and 6
and designs dk ∈ D1 (p, b, k), where k = 3, 4, we have ndkij = 2, for k
=1, 2,. . ., 8; i =1, 2, . . .p, j = 1, 2,. . ., p and their information matrices
Cdk are as given below.

Where Ip is an identity matrix of order p and 1p is a unit column
vector of ones. Clearly
Cdk given by (5.1) is completely symmetric
and Trace (
Cdk ) = 2 (p-1)2 which is not equal to the upper bound
given in (5.3).

Hence the designs d1, d2, d3, and d4 are not optimal. The
information matrix
Cdk given by (5.2) is completely symmetric
and Trace (
Cdk ) = 2 (p-1) (p-2) which is equal to the trace given in
(5.3). Hence the designs d5 and d6 are optimal in the sense of Kiefer
[15] and in particular minimizes the average variance of the best
linear unbiased estimator of all elementary contrasts among the
gca effects. To prove that the designs d1, d2, d3, and d4 are A- optimal,
we consider the following criteria. A design d* ∈ D (p, b, k) is said to
be A-optimal in D (p, b, k) if and only if Trace ((Vd*)≤Trace(Vd))
Here d* denotes designs d1, d2, d3, and d4 and d denotes designs
d5 and d6. The Trace (Vd*) is equal to 1/2 and Trace (Vd*) is which
is greater than 1/2.Hence designs d1, d2, d3, and d4 are an A-optimal.
Remark: The variances of the best linear unbiased estimators
of elementary contrasts among gca effects are equal in A-optimal
designs and also in optimal designs. It means that all the designs
are variance balanced, this fact is particularly attractive to the
experimenter, as it enables one to carry out the analysis of the
experiment in an extremely simple manner.
Now we state the following theorems.
Theorem: The existence of an Orthogonal Array (p2, p+1, p, 2)
implies the
existence of  different layouts A- optimal
incomplete block designs with parameters v = p2, b = p, k =p, r =1.
different layouts A- optimal
incomplete block designs with parameters v = p2, b = p, k =p, r =1.
(ii) existence  different layouts A- optimal
incomplete designs for Griffing’s method B with parameters v = p
(p+1)/2, b =p, k =p, r1 =1, for cross of the type (i, i) and r2 =2, for cross
of the type (i, j), where i, j = 1, 2, . . ., p, respectively.
different layouts A- optimal
incomplete designs for Griffing’s method B with parameters v = p
(p+1)/2, b =p, k =p, r1 =1, for cross of the type (i, i) and r2 =2, for cross
of the type (i, j), where i, j = 1, 2, . . ., p, respectively.
(iii) existence of p(p-1)/2 row-column designs for Griffing’s [9]
methods A and B with parameter v = p2, b = p, k =p , r =1 and v = p
(p+1)/2, b =p, k =p , r1 =1,for cross of the type (i, i) and r2 =2, for cross
of the type (i, j), where i, j = 1, 2, . . ., p, respectively.
Theorem:- The existence of an Orthogonal Array (p2, p+1, p,
2) implies the existence of  different layouts optimal
incomplete block designs for Griffings [9] methods C and D with
parameters v = p(p-1), b =p, k =p , r =1 and v = p(p-1)/2, b =p, k =p and
r =1, respectively.
different layouts optimal
incomplete block designs for Griffings [9] methods C and D with
parameters v = p(p-1), b =p, k =p , r =1 and v = p(p-1)/2, b =p, k =p and
r =1, respectively.
Example: Following Rao [19] we construct an orthogonal array
(25,6,5,2) of rp =5, the 4 orthogonal Latin squares with bordered
elements are (Table 2). This arrangement may be expressed in
five groups as given below Table 3. The above arrangement is an
orthogonal array (25, 6, 5, 2). From the above array we can derive
the designs for the four experimental methods described by Griffing
[9]. The procedure is explained below.
Table 2:

Table 3:

For Griffing methods A and B, we can take any two columns from
first group and corresponding columns from other groups i.e. 2, 3,
4, and 5 and arrange them in columns and then we obtain design for
methods A and B. Thus, we may obtain 14 different layouts designs
for each method A and method B. We may also obtain 10 different
layouts row-column designs for each of these methods A and B.
Remark: - Block and row column designs for methods A
and B containing crosses with last column of group 1 are neither
A-optimal nor optimal.
Example: Suppose we take the first two columns from first
group and corresponding columns from other groups i.e. 2, 3, 4,
and 5. Elements in brackets are considered cross between lines
and then we obtain the following design for Griffing’s experimental
methods A and B with parameters v = 25, b = 5, k =5, and r =1 and v
= 15, b = 5, k =5, and r =1, respectively, with the condition that the
cross (i, j) = (j, i) for method (2), where i < j = 1, 2, . . ., 5.
Figure 1 In the above design, considering rows as row blocks,
we may we may obtain row-column designs for Griffing’s methods
A and B respectively. From the above design we may also derive
designs for methods C and D by ignoring the first column and
considering (i, j) ≠ (j, i), in other columns, where i, j = 1, 2, 3, 4, and
5, with parameters v = 20, b = 5, k =5, and r =1. In Griffing’s method
C design considering (i, j) = ( j, i) , where i< j = 1,2, 3, 4, and 5, we
obtain a design for CDC method D with parameters v = 10, b = 5, k
=5,and r =2, Thus, from the above array we may obtain 10 different
layouts of designs for method C and 10 different layouts of designs
for method D.
Figure 1: Design for Griffing’s Method A and B.

Relation between Semi-Balanced Array (p(p-1)/2, p, p,
2) and Designs for CDC System
Consider a semi-balanced (p(p-1)/2, p, p, 2), where p is an odd
prime or power of odd prime. There are (p-1)/2 total sets in a
semi-balanced (p(p-1)/2, p, p, 2). If we identify the elements of semibalanced
array as lines of a diallel cross experiment and perform
crosses in any two sets among the corresponding lines appearing
in the same two sets, we get a mating design for diallel cross
experiment involving p lines with v =p2crosses, each replicated
once. The mating design can be converted into block design for
diallel cross experiment Griffing’s methods A with parameter v = p2,
b = p, k =p and r =1, considering rows as blocks. In the above design
considering the cross (i, j) = (j, i) where i < j = 0, 1, 2, . . ., p, we obtain
design for Griffing’s method B with parameters v = p(p+1)/2, b =p, k
=p , r1 =1,for cross of the type (i, i) and r2 =2, for cross of the type (i,
j), where i, j = 1, 2, . . ., p, respectively.. From block designs obtained
for methods A and B we may also obtain row-column designs for
Griffing’s methods A and B by considering columns as row blocks
with parameters v = p2, b = p, k =p and r =1 and v = p(p+1)/2, b =p, k
=p , r1 =1,for cross of the type (i,i) and r2 =2, for cross of the type (i,
j), where i, j = 1, 2, . . ., p, respectively. From the above mating design
deleting the first row and considering (i, j) ≠ ( j, i), where i < j = 0,
1, . . ., p we can also derive designs for methods C, with parameters
with parameters v = p (p-1), b =p, k =p , r =1. Considering (i, j) =
(j, i), where i, j = 0, 1, . . ., p, we obtain design for Griffing’s method
D with parameters v = p(p-1)/2, b =p, k =p and r =2. Thus, using
above techniques, we may obtain  different layouts designs for Griffing’s methods A, B, C and D. The
information matrices of block designs and row-column designs for
methods A and B are same as given in (1). So, block designs and
row-column designs for methods A and B are A- optimal. Similarly, the
information matrices of designs for methods C and D are the
same as given in (1), so designs for methods C and D are universally
optimal in the sense of Kiefer [15] and in particular minimizes
the average variance of the best linear unbiased estimator of all
elementary contrasts among the gca effects. These designs are
orthogonally blocked. Now we state the following theorems.
different layouts designs for Griffing’s methods A, B, C and D. The
information matrices of block designs and row-column designs for
methods A and B are same as given in (1). So, block designs and
row-column designs for methods A and B are A- optimal. Similarly, the
information matrices of designs for methods C and D are the
same as given in (1), so designs for methods C and D are universally
optimal in the sense of Kiefer [15] and in particular minimizes
the average variance of the best linear unbiased estimator of all
elementary contrasts among the gca effects. These designs are
orthogonally blocked. Now we state the following theorems.
Theorem 1: The existence of semi -balanced array (p(p-1), p,
p, 2) implies the existence of
different layouts of  A- optimal incomplete block designs and row-column designs for
Griffing’s [9] methods A and B with parameters v = p2, b = p, k =p
and r =1 and v = p(p+1)/2, b =p, k =p and r =1,respectively, where we
consider the cross (i, j) = (j, i) for method B, where i < j = 0, 1, 2, . . ., p.
A- optimal incomplete block designs and row-column designs for
Griffing’s [9] methods A and B with parameters v = p2, b = p, k =p
and r =1 and v = p(p+1)/2, b =p, k =p and r =1,respectively, where we
consider the cross (i, j) = (j, i) for method B, where i < j = 0, 1, 2, . . ., p.
Theorem 2: The existence of Semi -Balanced Array (p (p-1), p,
p, 2) implies the existence of  different lay outs of
optimal incomplete block designs v = p(p-1), b =p, k =p and r =1 and v
= p(p-1)/2, b=p, k=p and r=2, respectively, for Griffing’s [9] methods
C and D.
different lay outs of
optimal incomplete block designs v = p(p-1), b =p, k =p and r =1 and v
= p(p-1)/2, b=p, k=p and r=2, respectively, for Griffing’s [9] methods
C and D.
Example. If p =7, the residue classes 0, 1, . . . , 6 (mod7) form a
field . We write the 7 elements of GF (7) as 0, ±1, ±2, ±3 and hence
the key sets are, using the formula (7.1), where
(0, 1, 2, 3, 4, 5, 6), (0, 2, 4, 6, 1, 3, 5), and (0, 3, 6, 2, 5, 1, 4) (8.1)
second and third vectors are obtained from the first on
multiplying by 2 and 3, respectively. Writing (8.1) vertically (shown
in bold numbers) and generating the other columns by the addition
of elements GF (7) as indicated in (7.3). We obtain 21 columns as
shown below which is divided into three groups (Figure2).
Figure 2:

From the semi balanced array given above, we may obtain
designs for Griffing’s four experimental methods by superimposing
group 2 over group 1 or group 3 over group1 or group 3 over group
2. We superimpose group 2 over group 1 and obtain following
design for Griffing’s methods A and B with parameters v =49, b = 7,
k =7, and r1 =1 and v = 28, b = 7, k =7, and r =1, with the condition
that the cross (i, j) = (j, i), where i < j = 0, 1, 2, . . ., 6 (Figure 3).
From the above design we can derive designs for methods C,
and D
Figure 3:

(i) By ignoring the first row and considering (i, j) ≠ (j, i) in
other rows, where i < j = 0, 1, . . ., 6, for method C and
(ii) similarly ignoring first row and taking other rows and
also considering (i, j) = (j, i) in other rows, where i, j = 0, 1, . .
., 6, thus we may obtain  different layouts of designs for
method C and D.
different layouts of designs for
method C and D.
Conclusion
In the present article we have given block and row-column
designs for Griffing’s CDC system i.e for all methods A, B, C, and D
by using orthogonal array (p2, p+1, p, 2) and semi -balanced array
(p(p-1), p, p, 2). Block and row-column designs for methods A and
block designs for method C consume minimum experimental units
and are A-optimal and optimal, respectively. These designs are.
Read More About Current Trends on Biostatistics & Biometrics (CTBB) Click on Below Link:
https://lupine-publishers-biostatistics.blogspot.com/